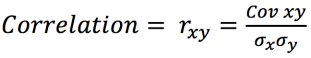Data Analytics – Text Mining the AOL 2006 Web Search Logs
By Kato Mivule
- In this example, we use R to implement text mining of the 2006 AOL web search logs.
- The 2006 AOL data set is multivariate – containing more than one variable.
- In this example, we are interested in the Query variable – containing the actual queries that were issued by users.

The 2006 AOL Web Search Logs WordCloud Sample
The AOL Dataset
- The AOL dataset published by AOL in 2006, is one of the few public datasets available that contain real web search logs.
- While data curators at AOL claimed to have “anonymized” the dataset by removing personal identifiable information (PII), researchers were able to re-identify some individuals in the published dataset.
- The AOL dataset contains the following five variables (attributes):
- AnonID: stores the identification number of the user.
- Query: stores the actual query that the user executed.
- QueryTime: The date and time the query was executed.
- ItemRank: AOL’s ranking of the query.
- ClickURL: The actual URL link that the user clicked on after querying.
Big Data Analytics
- The big data problem then becomes apparent; we are looking at about 1.5 gigabytes of data.
- There are about 20 Million web queries collected from about 650, 000 individuals over a 3 month period.
- However, I have only labeled a sample of about 500 Megabytes of data for machine learning purposes. We could use this sample as a start.
In this case we use R Studio for the implementation.
You can download R Studio here… https://www.rstudio.com/
You can download the 2006 AOL web search logs here… http://www.gregsadetsky.com/aol-data/
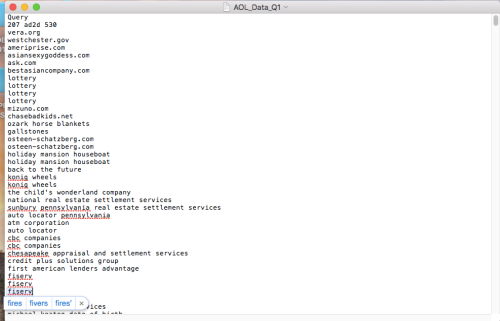
Step 1 – Select the Query attribute for analysis.
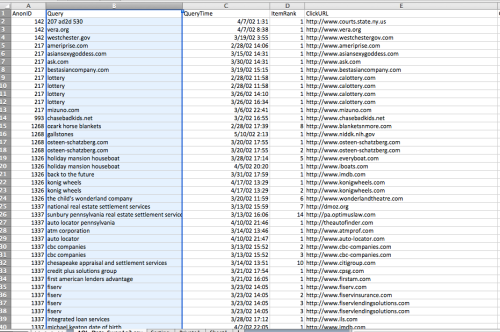
- We are interested in doing text-mining analytics on the actual queries that were issued by the users.
- In this example, we only use about 55,000 rows of data (queries) from the Query attribute – about 1.8 megabytes of data for our text analytics.
Step 2 – Load the text-mining libraries in R
- In this case, we use the “tm” library for text-mining.
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
Step 3 – Read/input the text file containing the query data into R Studio.
filePath1 <- "~/Desktop/AOL_QUERY_PRIVACY1/AOL_Data_Q1.txt"
- In this example, we use about 50,000 rows of text data, about 1.8 megabytes.
Step 4 – Load the data into a corpus
- Text is transformed in a corpus, which is a set of documents. In this case, each row of data in the query variable (attribute) becomes a document.
docs1 <- Corpus(VectorSource(text1))
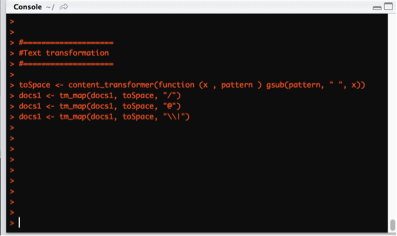
Step 5 – Do a Text Transformation
- Replace special characters,“/”, “@”, “|” , etc, with space.
- The tm_map() function is used to replace special characters in the text.
toSpace <- content_transformer(function (x , pattern )
gsub(pattern, " ", x))
docs1 <- tm_map(docs1, toSpace, "/")
docs1 <- tm_map(docs1, toSpace, "@")
docs1 <- tm_map(docs1, toSpace, "\\|")
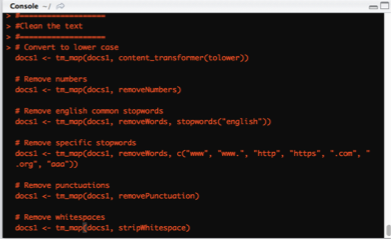
Step 6 – Transform and clean the text of any unnecessary characters.
# Transform text to lower case
docs1 <- tm_map(docs1, content_transformer(tolower))
# Transform text by removing numbers
docs1 <- tm_map(docs1, removeNumbers)
# Transform text by removing english common stopwords
docs1 <- tm_map(docs1, removeWords, stopwords("english"))
Transform text by removing specific stopwords. These words tend to be very common in the AOL Web search logs and offer no meaning at this point, but are a distraction in the analytics by giving us unneeded stats – “www”, “www.”, “http”, “https”, “.com”, “.org”, “aaa”.
docs1 <- tm_map(docs1, removeWords, c(“www”, “www.”, “http”, “https”,
“.com”, “.org”, “aaa”))
# Transform text by removing punctuations
docs1 <- tm_map(docs1, removePunctuation)
# Transform text by removing whitespaces
docs1 <- tm_map(docs1, stripWhitespace)
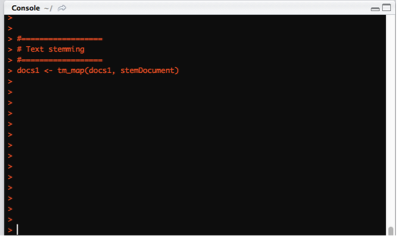
Step 6 – Transform by Text Stemming – reducing English words to their root.
- In this step, English words are transformed and reduced to their root word, for example, the word “running” is stemmed to “run”.
docs1 <- tm_map(docs1, stemDocument)
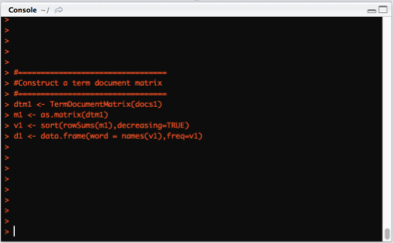
Step 7 – Construct a document matrix.
- A document matrix is a table made up of each unique word in the text and how many times it appears – basically the table of word frequency.
- The column names in the table are each unique word and row names represent the documents in which those words appear.
- The TermDocumentMatrix() function from the “tm” library is used to generate the document matrix.
- The document matrix is what we use for the frequency analytics of words in the text to finally derive conclusions.
- The matrix() function transforms the TermDocumentMatrix into a matrix.
- The sort () function transforms text by sorting it in descending or ascending order.
- The frame () function creates is a list of variables of the same number of rows with unique row names, given class “data.frame“, in this case we create variables of words and their frequencies.
- The head () function returns the top 10 most frequent words in the data.frame, d1.
dtm1 <- TermDocumentMatrix(docs1)
m1 <- as.matrix(dtm1)
v1 <- sort(rowSums(m1),decreasing=TRUE)
d1 <- data.frame(word = names(v1),freq=v1)
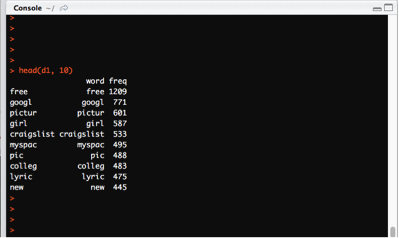
head(d1, 10)
Step 8 – Do a frequency analysis
- At this point we can take a look at the most frequent terms, or in this case queries issued.
- The findFreqTerms() function is used to find the frequent terms or words used in the term-document matrix.
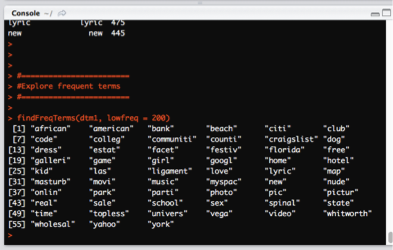
- In this case, we want to get words at appear at least 200 times.
findFreqTerms(dtm1, lowfreq = 200)
Results from the head () function
Words that appear at least 200 times.
Step 9 – Plot the word frequencies
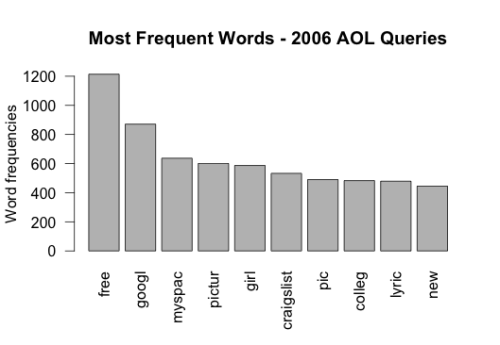
- The barplot () function is used to plot the 10 most frequent words from the 2006 AOL sample we used.
barplot(d1[1:10,]$freq, las = 2, names.arg = d1[1:10,]$word, col =“grey”,
main = "Most frequent words", ylab = "Word frequencies")
Step 10 – Generate a word cloud of words that appear at least 200 times.
- The wordcloud () function from the wordcloud library is used to plot the word cloud for the queries under analysis.
- The words parameter in the wordcloud represents the words to be plotted.
- The freq parameter represents the word frequencies.
- The freq parameter sets a limit on words with a certain frequency to be plotted.
- The words parameter sets the maximum number of words to be plotted.
- The order parameter plots words in random order. If set to false, words will be will be plotted in decreasing frequency.
- The per parameter vertically proportions words with a 90-degree rotation.
- The colors parameter sets the color of words from the least to most frequent.
set.seed(1234)
wordcloud(words = d1$word, freq = d1$freq, min.freq = 50, max.words=200, random.order=FALSE, rot.per=0.35,colors=brewer.pal(8, "Dark2"))
The word cloud.

Conclusion
From this data sample, we can conclude that terms such as “Google”, “Yahoo”, “Free”, “Myspace”,”craigslist”, were popular search terms then on the AOL search engine in 2006.
References
-
Michael Arrington, “AOL Proudly Releases Massive Amounts of Private Data”, TechCrunch, Accessed Feb 17 2016, Available Online at: http://techcrunch.com/2006/08/06/aol-proudly-releases-massive-amounts-of-user-search-data/
-
Michael Barbaro and Tom Zeller, “A Face Is Exposed for AOL Searcher No. 4417749”, New York Times, Accessed Feb 17 2016, Available Online at: http://www.nytimes.com/2006/08/09/technology/09aol.html
-
Greg Sadetsky, “AOL Dataset”, Accessed Feb 17 2016, Available Online at: http://www.gregsadetsky.com/aol-data/
-
com – Text-mining and Word Clouds – http://www.sthda.com/english/wiki/text-mining-and-word-cloud-fundamentals-in-r-5-simple-steps-you-should-know